
Have you been told you need to scrape leads to do cold email well? You don’t. Most cold email runs fine on bought lists from Apollo or similar databases.
I work with founders who came in thinking lead scraping was a prerequisite, and the same conclusion shows up: scraping is a power move for specific cases, not a requirement. This article walks through when scraping beats buying, when it doesn’t, and the AI qualification step every scraping pipeline needs.
Lead scraping is optional, not required
The default cold email playbook works fine without scraping. Apollo, ZoomInfo, Clay, and similar databases give you a list good enough to test the channel and get to first meetings. I run almost every founder’s first in-house cold email campaign on a bought list.
Scraping is a tool for specific situations. The three where it matters:
- Your ICP isn’t covered by the major databases
- You want intent signals the databases can’t see (LinkedIn engagement, event attendance, specific job-page visits)
- You’re building category-specific lists (Google Maps by business type, conference attendees by event)
If none of those apply, buy a list from Apollo and skip the scraping pipeline entirely. The setup cost isn’t worth it for broad ICPs.
When buying a list is the right call
When a founder asks me whether they should scrape or buy, I send them to Apollo or ZoomInfo if any of these are true:
- Your ICP is broad. “Marketing directors at B2B SaaS companies 50 to 500 employees” is covered by every major database.
- You need volume fast. A bought list can be ready in an hour. A scraping pipeline takes 4 to 12 hours to build the first version.
- Your buyer fits established categories. The database has them tagged. You don’t need custom filtering.
- You don’t have engineering hours. Scraping requires building or buying a pipeline. Buying requires a credit card.
Most B2B services and SaaS businesses are in this camp. The databases are good enough.
When scraping beats buying
Scraping wins in narrower cases. I send founders down the scraping path when:
- Niche ICPs not in databases. If you sell to “fishing charter operators in Florida” or “independent veterinary clinics,” Apollo’s filters can’t find them. Scraping Google Maps can.
- Intent signals databases can’t see. LinkedIn engagement on a specific post, attendees of a specific event, visitors to a specific job page. The signal typically beats the database in reply rate.
- Category-specific bulk lists. Local businesses by type from Google Maps, SaaS users by tech stack from BuiltWith, podcast guests by show from listening platforms.
- Faster ICP iteration. Once you have the scraping pipeline built, testing a new ICP is hours, not a database subscription.
The common thread: scraping wins when your ICP is too specific for the database or when the signal source matters more than the contact data.
The three scraping categories
Scraping isn’t one thing. The three distinct categories I work across, each with different economics:
- Pre-filtered target lists. Google Maps by business type, BuiltWith by tech stack, Crunchbase by funding stage. The filter is upstream, so qualification is lighter.
- Engagement scraping. LinkedIn post reactions, comments, post engagers. The signal is intent, but the noise is high (other consultants, journalists, juniors).
- Enrichment scraping. Filling missing fields on an existing list (emails, titles, company size). Lower lift, lower payoff than the first two.
Each category needs a different pipeline and a different qualification step. The next section is the one most pipelines skip.
The required step nobody talks about: AI qualification
Raw scraped lists are noisy. In my experience, engagement scraping lists are 40% to 60% wrong-fit (other consultants, competitors, journalists, juniors). Even category-filtered lists (Google Maps) have 20% to 40% noise (chains, franchises, wrong-stage businesses). I won’t ship a scraped list to a sender without this step running first.
The qualification step turns a scraped list into a usable list. The pipeline:
- Run the scrape
- For each lead, pass profile data (name, title, company description) to an AI model
-
Ask the model: “Is this person a fit for my ICP? Return JSON
{qualified: bool, reason: string}.” - Filter to qualified leads only
Without this step, you waste email-finder credits on wrong-fit leads, send to people who won’t reply, and tank your overall reply rate. The qualification step is the difference between scraping that works and scraping that costs money for nothing.
A concrete qualification prompt
The prompt structure I use:
You are a sales qualifier. The ICP is:
- Role: VP of Marketing or Head of Marketing
- Company: B2B SaaS, 50-500 employees
- Disqualifiers: agencies, consultants, anyone with "founder" in title, anyone at companies outside the size band
Input lead:
- Name: [name]
- Title: [title]
- Company: [company name]
- Company description: [description]
Return only this JSON: {"qualified": true|false, "reason": "<short reason>"}The explicit disqualifiers matter more than the qualifications. I learned this after running the same pipeline without them and watching the drop rate sit at 10% when it should have been 50%. Tell the model what to reject and you cut the noise. Tell it only what to keep and it’ll be too permissive.
Expected drop rate: 40% to 60% for engagement scraping, 20% to 40% for category-filtered scraping. The lower drop rates mean less noise upstream.
What scraping actually costs
The honest cost of a scraping pipeline I run:
- Scraping tools (Apify Starter from $29, Outscraper pay-as-you-go from about $3 per 1,000 results, custom Serper queries): $30 to $200 per month at modest volume. BuiltWith for tech-stack data is more expensive ($295+ per month).
- Qualification step (Claude, GPT API calls): $10 to $50 per month at 2,000 to 5,000 leads per month
- Email finder for verified emails on scraped contacts: $50 to $100 per month
- Setup time: 4 to 12 hours to build the first version of the pipeline
Total: $90 to $350 per month plus setup time. Compare to Apollo Basic at $59 per month or Professional at $99 per month for the broad-ICP equivalent.
The cost difference matters only when the scraped list outperforms in reply rate. If reply rate is the same, just buy.
The math: scraped cost vs bought cost
Bought lead cost: about $0.10 to $1.00 per lead at typical Apollo tier.
Scraped cost: about $0.20 to $2.00 per qualified lead (after scraping, qualification, and verification). Time matters too, but if amortized across volume, the per-lead cost is in this range.
The math wins when intent is high. An intent-based scraped list (LinkedIn post engagers, event attendees, specific tech-stack users) typically lands 5% to 15% reply rate vs 1% to 3% for buy-and-blast. At those reply rates, the cost-per-meeting math flips in favor of scraping.
When intent is low or ICP is broad, the bought list wins. See cost per meeting from cold email for the formula. For the highest-volume scrape that does pay off, see scraping Google Maps for cold email.
When the scraped-list math wins
When I greenlight a scrape, at least two of these are true:
- Buyer intent is observable. Someone engaged on a specific post, attended an event, hired a specific role
- ICP is niche. The databases don’t have the buyer in clean categories
- You can build the pipeline once and reuse it. First scrape: 8 hours. Second scrape: 30 minutes.
- You have time to test reply rate before scaling. Scraping payoff comes from the higher reply rate; if you can’t measure it, you can’t trust it
If only one of these is true, buying the list is the cleaner call.
A simple decision tree
The decision I run with founders:
| Situation | Decision |
|---|---|
| Broad ICP, need volume fast | Buy from Apollo |
| Niche ICP, no database coverage | Scrape with qualification step |
| Engagement-based intent signal | Scrape with mandatory AI qualification |
| Tech-stack-based intent signal | Scrape from BuiltWith with qualification |
| First cold-email test, any ICP | Buy first, scrape if buying underperforms |
| Repeat customer base or known prospect list | Skip both, use existing data |
I send most founders running cold email for the first time to buy. Scraping is the move once you know the channel works for your business.
FAQ
Can AI scrape leads? AI helps with the qualification and enrichment steps more than the scraping itself. The scrape is usually a specific tool (Apify, Outscraper, custom) and AI filters the output. The combination of scraping plus AI qualification is the modern workflow.
Best AI tools for scraping leads in 2026? For the scraping itself: Apify, Outscraper, custom Serper queries, BuiltWith for tech-stack. For qualification: Claude or GPT API with structured JSON output. For email finding: Hunter, Apollo’s API, Snov.
Is lead scraping worth it for cold email? Worth it when your ICP is niche, when buyer intent is observable, or when you’ll reuse the pipeline across campaigns. Not worth it for broad ICPs covered by Apollo or for one-off campaigns where setup cost outweighs benefit.
How do I qualify scraped leads?
Run each lead through an AI model with explicit ICP criteria and disqualifiers. Ask for {qualified, reason} JSON output. Filter to qualified-only. Expected drop rate: 40 to 60% for engagement scraping, 20 to 40% for category-filtered scraping.
Scraping vs buying lists for cold email? Buy when ICP is broad and database coverage is good. Scrape when ICP is niche or buyer intent is observable. The AI qualification step is required either way for scraped lists.
Bringing it home
Lead scraping is a power move, not a prerequisite. Most cold email works fine on bought lists from Apollo or similar databases.
Scraping wins when ICP is niche, when intent is observable, and when you’ll reuse the pipeline. The AI qualification step is non-negotiable when you do scrape, otherwise the noise tanks your reply rate.
The decision tree: broad ICP, buy. Niche or intent, scrape. First cold-email campaign of your life, buy first.
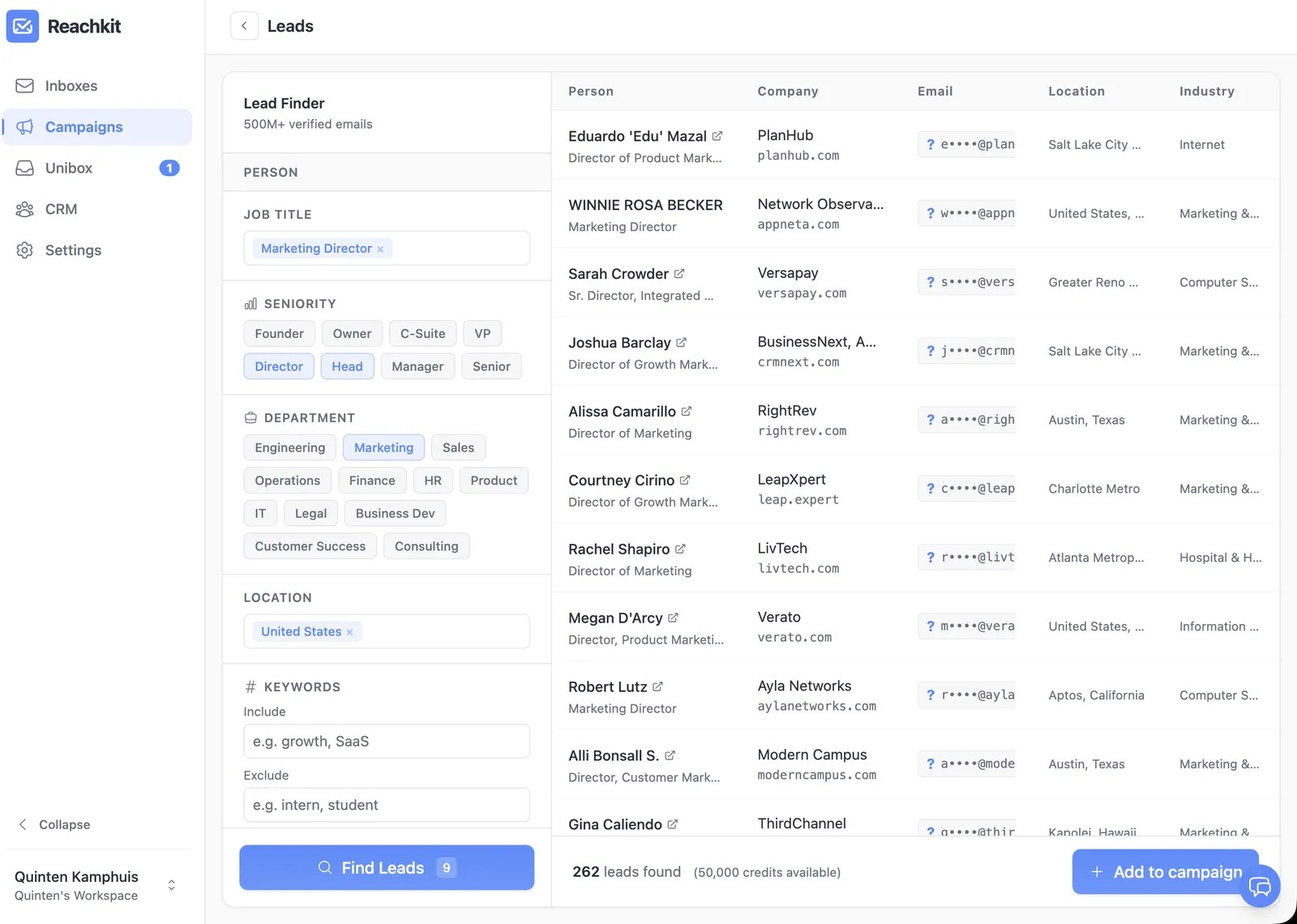
Run the decision tree on your own list this week, or try Reachkit free to see what the broad-ICP path actually looks like before deciding if scraping is worth the build.